Following up from my original post introducing rare, I paused development for a bit as it suited my need for a while, but recently restarted as I felt like its biggest flaw was resolvable.
What is rare?
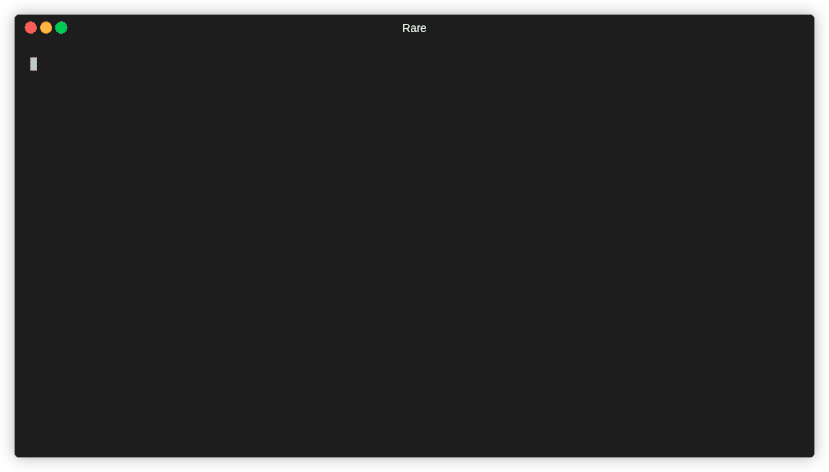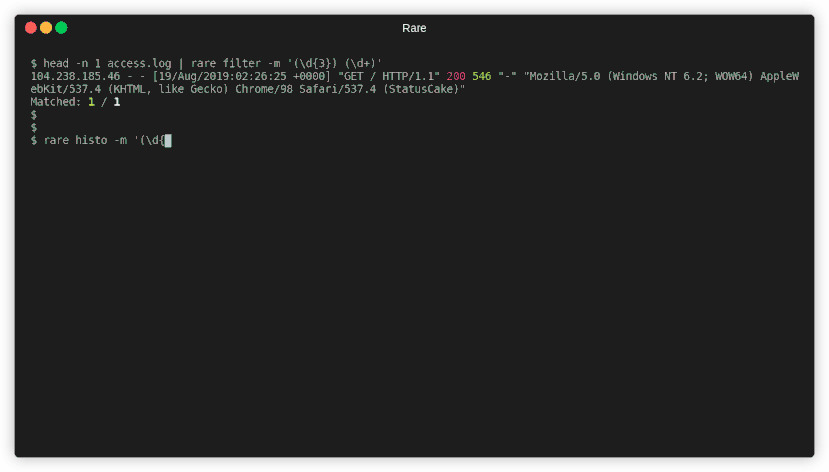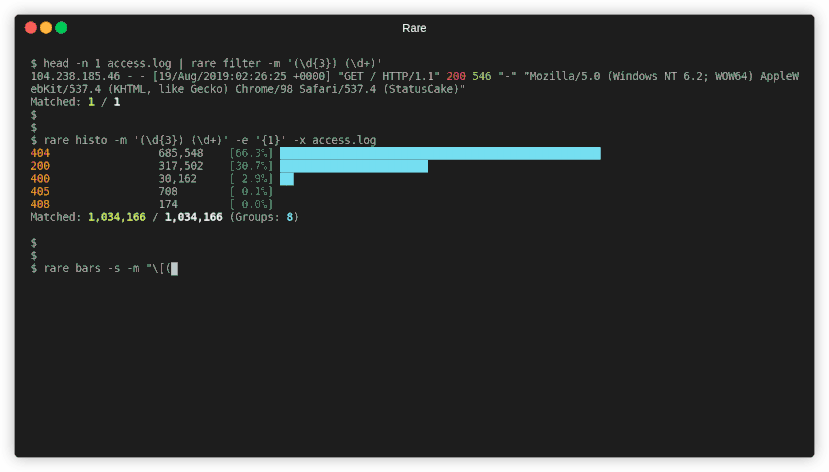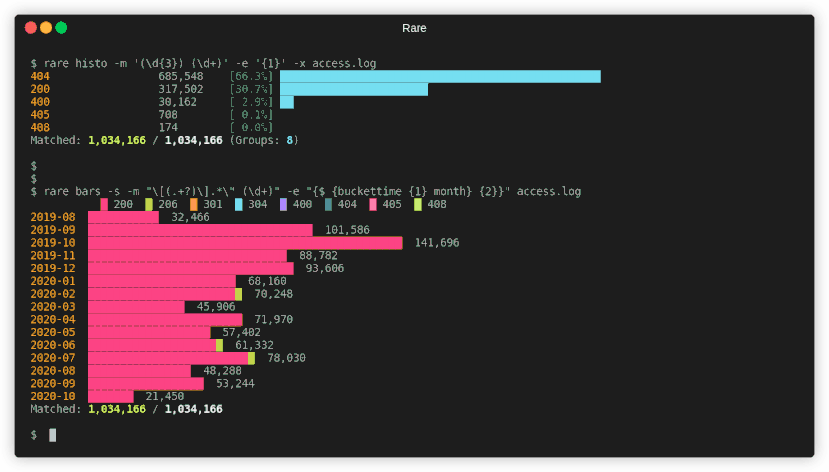
As a quick recap of the previous post, rare is a realtime regex extractor and evaluator. This allows you to visualize data from a mass of text files (eg. log files) quickly and while the scan is in-progress. It includes visualizations like bargraphs, histograms, tables, and simple filter (grep-like).
You can find the source and binary downloads on github
The Problem
Golang's implements regex using re2, which comes with the guarantee that runtime increases linearly with the size of input (as opposed to other algorithms that may increase exponetially). Exponential algorithms introduces the application to ReDoS attacks (Regular Expression Denial of Service Attack), so when the input might be uncontrolled, it's best to use re2.
For rare the input is often log files or other data. And even if the input is uncontrolled, when used as a tool, the user is in control of the execution (And you can always ctrl+c of course). This means that in most cases this issue should be manageable.
Benchmarking re2
For a while I worked on optimizing other parts of rare that I had direct control over. This included optimizing expressions, batching the data going through the channels, and decreasing file io using an optimized read-ahead.
After all that work, there was really only one thing I could reasonably increasee the performance of (and it was pretty obvious): the regex implementation.
$ du -sh testdata/
84M testdata/ (~ 1.5 GB decompressed)
# Version ~ 0.2.0-rc.2
$ go run . --profile=re2 table -z -m "\[(.+?)\].*\" (\d+)" -e "{buckettime {1} year nginx}" -e "{bucket {2} 100}" testdata/*
$ go tool pprof -http=:8080 re2.cpu.prof
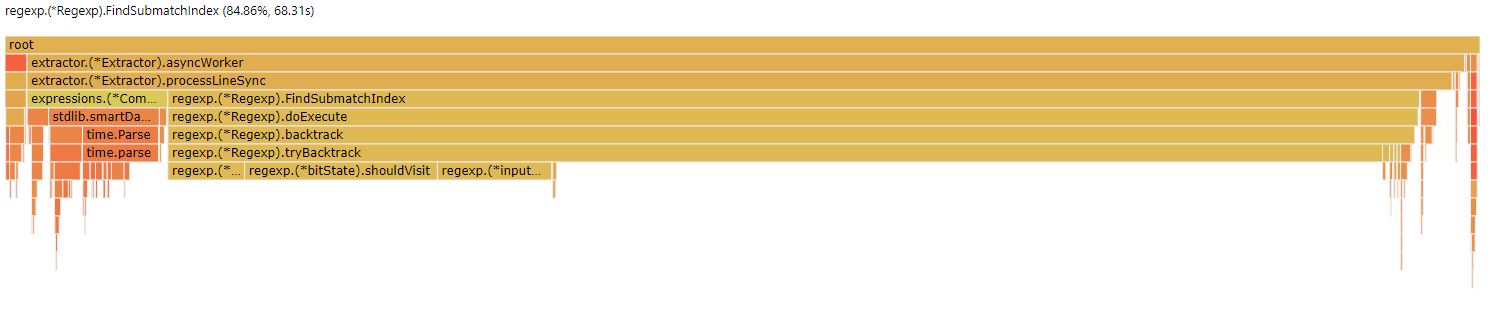
Why?
There is of course the question of "why do this at all?" Let's be honest, half of this was for fun, and because I could. The other half is that I always felt that rare lacked performance in certain situations compared to other tools, and being able to improve that was critical to its main use, which is to speed up seeing results of large text queries.
PCRE2
PCRE2 (libpcre2) is significantly faster for non-trivial regexs. A simple benchmark shows it can be both faster and use less CPU time by a factor of 4-5x. It's also common and popular enough that adoption wouldn't be an issue. That led to the next step, which was a proof-of-concept.
Implementing PCRE2 in CGO
Besides reading up on cgo, much of the port to go is based on the pcre2 demo from the documentation.
Because PCRE2 requires per-instant memory (Stack if JITd, the ovec result vector, etc), I changed the interface implementation slightly, but try to stick close to re2's interface as closely as possible (Matter of fact, re2 can easily implement the interface). Each goroutine will hold its own instance, but reference the static data (The compiled regex) only once. To free any created memory, we leverage go's runtime.SetFinalizer to cleanup after ourselves.
You can see the full implementation on github, but execution effecetively boils down to:
func (s *pcre2Regexp) FindSubmatchIndex(b []byte) []int {
if len(b) == 0 {
return nil
}
bPtr := (*C.uchar)(unsafe.Pointer(&b[0]))
rc := C.pcre2_match(s.re.p, bPtr, C.size_t(len(b)), 0, 0, s.matchData, s.context)
if rc < 0 {
return nil
}
for i := 0; i < s.re.groupCount*2; i++ {
s.goOvec[i] = int(*(*C.ulong)(unsafe.Pointer(uintptr(unsafe.Pointer(s.ovec)) + unsafe.Sizeof(*s.ovec)*uintptr(i))))
}
return s.goOvec
}
Benchmarks
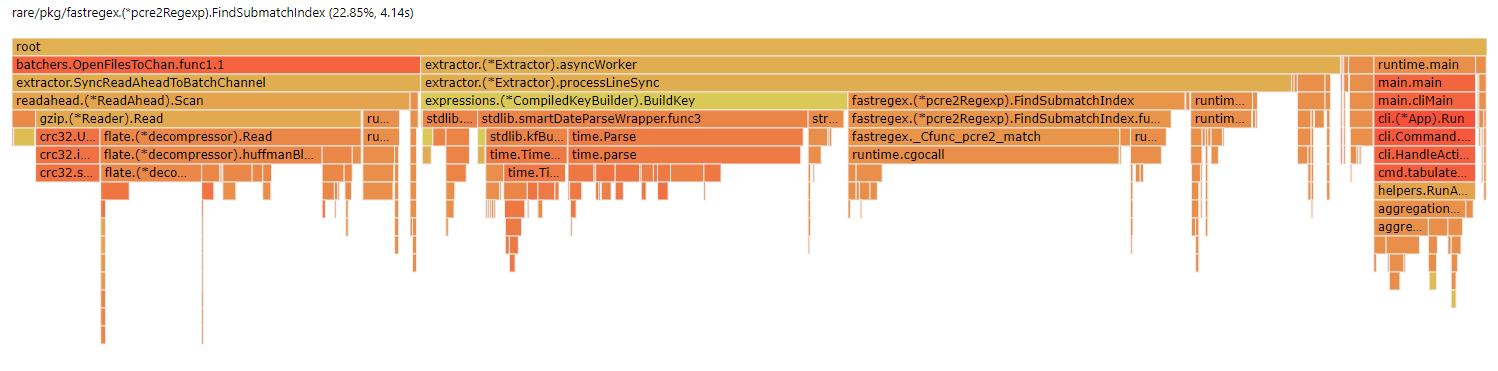
As you can see, despite cgo's overhead, pcre is significantly faster than re2. With the same test data, pcre computes all the regex's in 4.14s, and re2 does it in 68.31s. This evens out the load between the major parts of the program fairly evenly (Aggregation, regex extraction, key-building, and file IO).
Shortcomings
- As mentioned above, PCRE is non-linear, meaning that in some very complex cases that this regex might be slower than re2. Given what people are usually looking for in log-files, I consider this unlikely.
- PCRE is written as a CGO dependency, meaning that rare now incurs the overhead associated with cgo because of various safety and security measures. This can be significant per-call, so work has been done to insure that only one C-call happens per regex evaluation by frontloading anything that can be, and delegating this to a new "regex instance" (since we're often processing text in many go-routines).
- This also means that the binary is now dynamically linked, since it depends on
libpcre2-8, which some consumers might not be used to. For this reason, we include both pcre and non-pcre versions. - And lastly, because PCRE is easiest to obtain on linux, we only compile PCRE on linux and continue to maintain a backwards-compatibility layer to go's RE2
Bonus: Expression Analysis
Albeit smaller, another shortcoming could occur if the user used the expression helper-logic to assist in computing static expressions. For instance, let's examine the expression {multi 10 10}. This effectively generates a multi function that takes in 2 static-functions (each with the string-value of 10). So that means each time an expression is evaluated, we have to parse 2 integers, multiple them together, and stringify.
It obviously doesn't make sense to do this every time. Instead, what I did, is when the expression is compiled I pass the expression tree a dummy-context to see if it needs to query the context in order to evaluate an expression. The context contains the ability to lookup a key by name or value (usually the results of your regex). Failure to use context implies that the expression is constant (Thare are some exceptions to this reasoning, but none currently exist in rare).
If the expression does seem to be constant based on the above definition, then it is evaluated during compilation, and the result is treated as a literal rather than a tree. I was able to see significant improvements in performance relative to the expression complexity. In no case would the performance become worse (Except for one additional expression evaluation at the beginning to figure this out).